
Public Time-Series Benchmarks Are Mostly Useless
Why your “SOTA” TSFM/LLM numbers won’t survive the real world

TL;DR
Even if you scrub direct leakage and dataset contamination, public time-series benchmarks still inflate results because of temporal confounding—global events that couple train and test. Until models are frozen and scored on future, proprietary data with independent auditing, leaderboard wins are marketing, not evidence.
The uncomfortable truth
Time-series foundation models (TSFMs) are sold on the promise of learning universal patterns. But the very thing that makes them powerful makes most evaluations meaningless: when the world shocks in sync (COVID, energy crisis, supply-chain whiplash), thousands of series move together. If your training window spans the shock and your test window lives in the same era, the model is effectively pre-briefed. That’s not generalization; it’s era recognition.
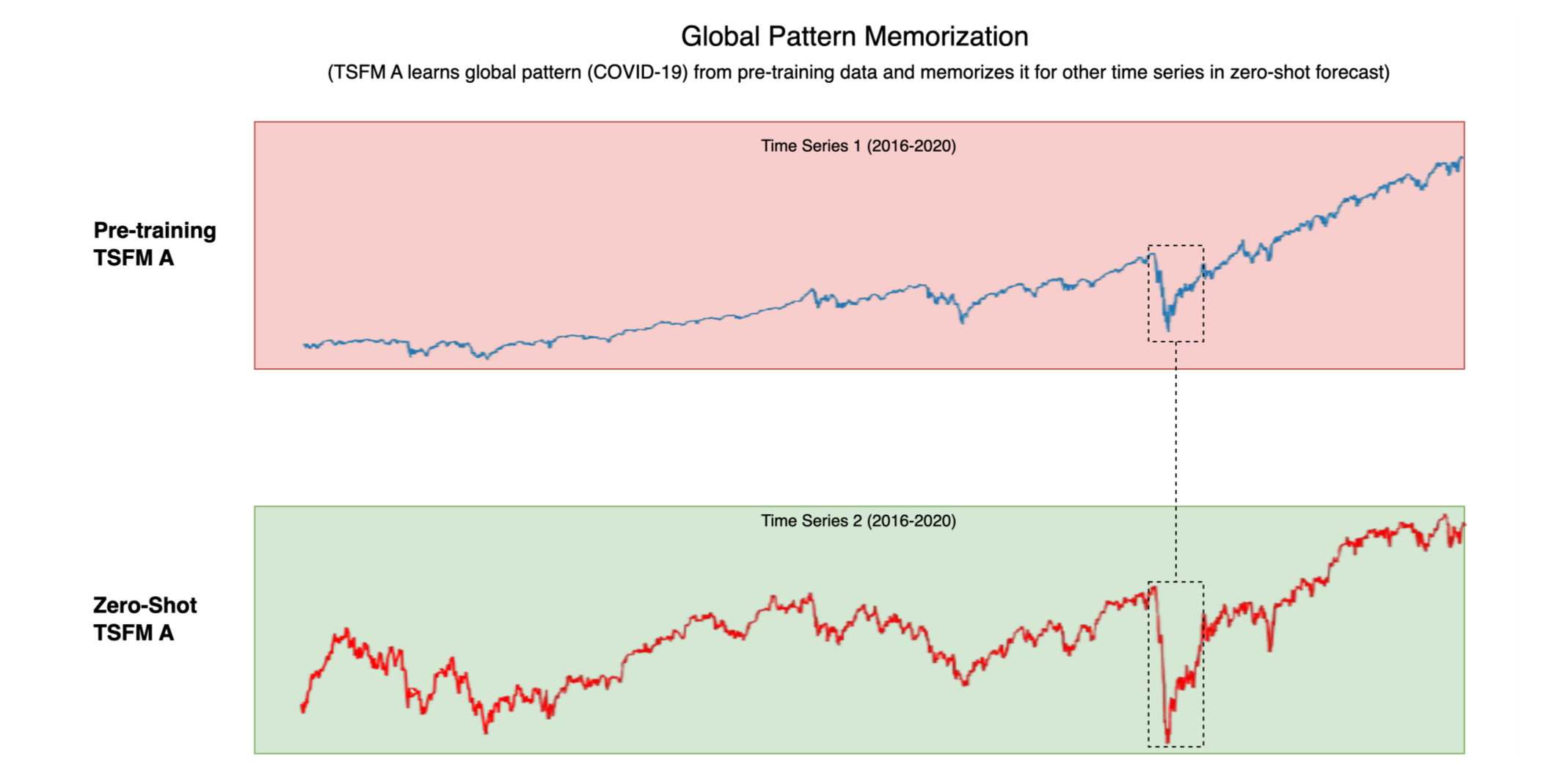
This is indirect leakage via confounding, not simple record overlap. You can dedupe meticulously, rename nothing, publish clean splits—your scores still won’t hold when the regime changes.
